Overview
Sailing upwind requires constantly balancing two competing forces: sailing at a tighter angle to the wind (closer to straight upwind) covers less distance but moves slower, while sailing at a wider angle moves faster but covers more ground. This project tackles that tradeoff by simulating the aerodynamics from first principles, then training a reinforcement learning agent to find time-optimal tacking routes through stochastic wind fields.
The pipeline has three stages:
- A Lattice Boltzmann wind tunnel in Wolfram Mathematica computes lift coefficients for a two-sail rig (mainsail + jib) across combinations of wind speed (5–20 knots), boat angle (37.5°–52.5° off the wind), and sail angle (0°–15°)
- A PPO agent navigates a 1000×1000 grid with a spatially varying wind field, using the precomputed lift data to determine boat speed at each heading
- The trained agent’s path is animated over the wind vector field in real time
Aerodynamics Simulation
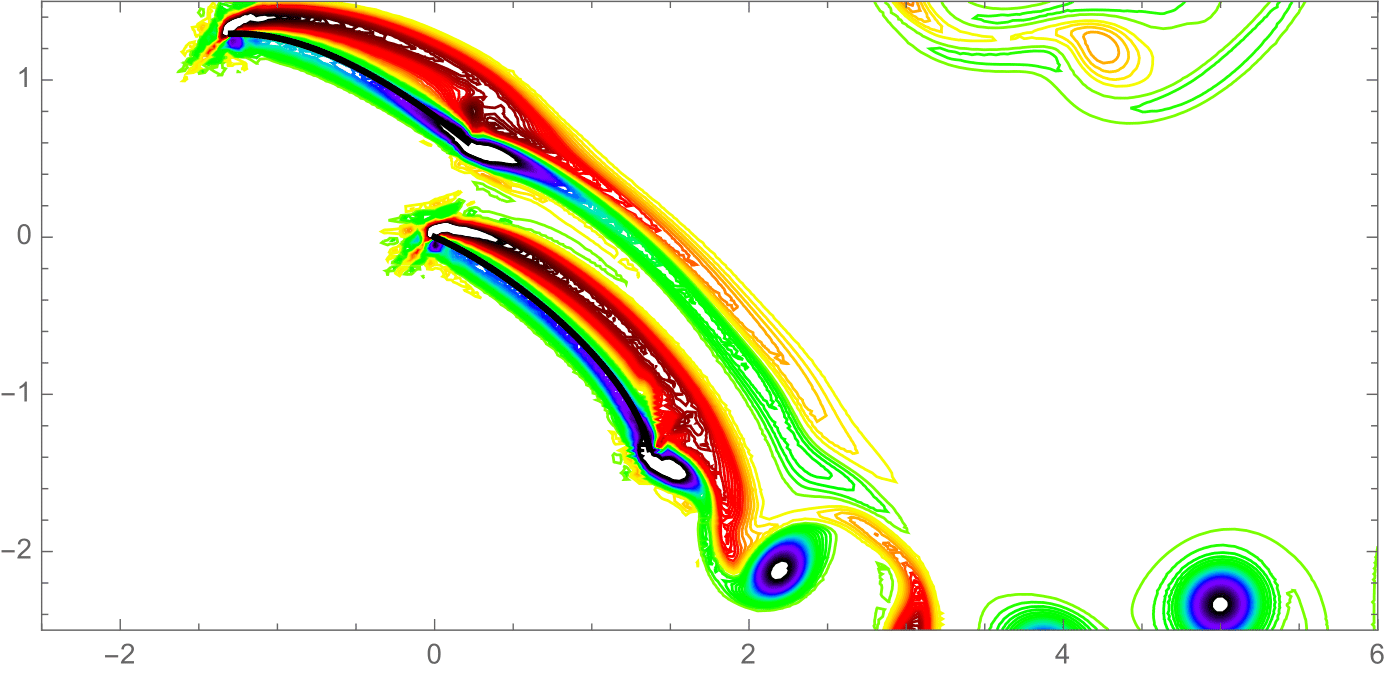
Sail shapes are defined using Bézier curves with manually tuned control points, constrained to match real-world arc lengths:
| Sail | Arc Length | Chord |
|---|---|---|
| Jib | ~169 cm | 163 cm |
| Mainsail | ~199.5 cm | 194 cm |
The Lattice Boltzmann wind tunnel runs both sails simultaneously. At each time step, 8 particles per grid point advect in their respective directions; collisions trigger velocity redistribution. Vorticity fields reveal the pressure differential across each sail, and lift coefficients are extracted at the center of effort of each sail. Total lift is computed as:
where (air density used in simulation), , .
Simulations were run for every combination of wind speed, boat angle, and sail angle, parallelized across kernels. The sail angle yielding maximum lift was retained for each (wind speed, boat angle) pair — for almost all cases this was 0°.
Reinforcement Learning Environment
A custom OpenAI Gym environment built on the 1000×1000 coordinate grid. The agent starts and ends at random positions, with a discrete action space of 7 boat angles (37.5°–52.5° off wind) plus a tack action. Wind varies spatially: base speed ranges from 7–18 knots with ±3 knot variation per cell, and direction shifts ±20° per cell.
The observation space is 252-dimensional, encoding:
- Current position, wind speed and direction, angle to goal, distance to goal
- Layline status, tack count, boundary proximity
- Simulated future positions and rewards for all 8 actions
- Full flattened wind field
Reward Shaping
- Positive reward proportional to VMG (velocity made good toward the goal)
- Time penalty proportional to per step, where is the lift force
- +1,000 for tacking on the layline; −1,000 for tacking off the layline
- −10,000 and episode termination for two consecutive tacks
- +50,000 (minus time penalty) for reaching the goal
- −50,000 for going out of bounds
Training
The agent was trained with PPO using a learning rate of 0.003, entropy coefficient of 0.1 (higher than default to encourage exploration), and a discount factor of 0.95. Training ran in 100,000-step blocks until mean reward over 10 evaluation episodes exceeded 1,000,000.
Results
The trained PPO agent successfully learned to tack upwind, producing a zigzag path that a competitive sailor would recognize as tactically correct — sailing on the lifted tack toward the layline, tacking at the right moment, and heading up to the mark. The agent also learned to seek out patches of stronger wind (gusts) and lifts to reduce distance sailed, consistent with real racing strategy.
Limitations and Future Work
The current model has several simplifications: sail shapes were estimated rather than measured, sails are modeled as rigid (real sails deform under load), water current is not modeled, and the wind field is synthetic rather than meteorological. Only upwind sailing is modeled — downwind legs requiring a spinnaker are not included.
Future directions include adding accurate sail measurements and a vang parameter to control mainsail twist, introducing downwind sailing with a spinnaker, replacing the synthetic wind field with real race-day data for post-race route analysis, increasing LBM resolution using cloud computing, and extending path optimization to a full race course with multiple marks.